Evolving the next generation of AI
Published:
The maximum path sum problem
In computer science, the maximum path sum problem is a popular optimization problem posed as follows. Given a triangular grid of rows, start at the top and move to the bottom by stepping each time to one of the two adjacent entries below. The objective is to maximize the sum along the path.
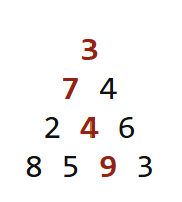

The naive brute-force solution is not computationally feasible because the number of possible paths grows exponentially with the number of rows. For a grid with 100 rows, the number of possible routes that must be checked is $2^{99}$.
The optimal solution utilizes a technique known as Dynamic Programming (DP). You start from the bottom cells and store their values in a table for easy look-up later. This table will store the maximum sum youʼll obtain if you descend from any particular cell to the bottom, which for the bottom nodes is their own value. As you climb up the tree, you populate the table value for a node as the sum between its own value and the larger of the table values for its two adjacent entries below. The final answer is computed at the top cell. This algorithm runs in $O(n^2)$
time, because each node is processed only once. This solution to the max-sum problem starts by maintaining a large pool of candidates (the bottom cells), storing their solutions, and systematically recombining them to build a global optimum. In this essay, I will argue that the next generation of AI should be built with the same recipe.
Evolutionary optimization vs. Gradient-based learning
The space of neural network topologies, just like the number of paths in the triangular grid, is very large — in fact, it is infinite. In this infinite-dimensional space, the set of feedforward connected and differentiable networks occupies a very tiny subset. Additionally, gradient descent explores an even smaller neighborhood within this subset as it inches along smooth slopes in search of minima. From this perspective, training a transformer model is like committing to a single path in the grid and greedily trying to tweak the cells in hopes of obtaining the optimal solution.
Evolutionary optimization on the other hand mirrors the DP solution above in spirit. Instead of committing to a single path, it explores many paths at once. It maintains a population of candidate solutions, which can be recombined so that useful traits discovered in one branch can be utilized in another. Like Dynamic Programming, it breaks a vast search into smaller, overlapping subproblems. A clever wiring pattern that stabilizes control in one environment might later be repurposed in a completely different context, forming the backbone of a new behavior. While gradient descent is local, greedy and narrow, evolution is global, diverse, and compositional.
A large body of work has compared evolutionary methods with gradient descent. Several studies have shown that evolutionary strategies (ES) for example approximate gradient descent over the distribution of the parameters rather than the parameters themselves. While ES captures two core ingredients of evolution—selection (prefer high-fitness samples) and mutation (stochastic perturbations)— it typically assumes a fixed network topology. As a result, standard ES lacks crossover of architectural building blocks, the recombination operator that enables compositional reuse of parts. Practically however, when gradients are available, reliable and cheap, and the optimization problem at hand is not difficult, gradient based methods are more sample efficient than evolutionary strategies.
Evolutionary optimization in robotics
Where evolutionary methods truly shine is when the loss landscape is spiky, gradients are unavailable or have high-variance. This is especially true in Robotics.
Robots today are remarkably clumsy and slow when it comes to manipulating fine deformable items like clothes. Garment manipulation is in fact a very difficult challenge in robotics because clothes are deformable and have state spaces orders of magnitudes larger than 6DOF rigid bodies. Additionally, folding clothes requires interaction with structures like wardrobes and hangers, as well as people. Simulating clothes digitally is also very difficult. A shirt can touch itself in a thousand places. To maintain physical fidelity, collision avoidance algorithms must be run simultaneously on a lot of points.

Current approaches to tackling this challenge mostly rely on a combination of Reinforcement Learning (RL) and Vision Language Action (VLA) models. But the crux of the problem with these approaches is that gradients have high variance in the jagged loss landscape introduced by deformables. A 3 mm difference in fold angles could mean the difference between success and failure. Exacerbating the problem is the fact that rewards are sparse and hard to define — what are the mathematical properties of a well-folded shirt?
Evolution on the other hand searches over behaviors rather than through gradients. They can slowly optimize over controllers through the selection, crossover and mutation operators as long as performance can be measured in some way. In robotics, this opens a vast search space that gradient based methods canʼt easily reach: sensorimotor loops that exploit friction; neural circuits that adapt to contact events, etc.
Quality diversity methods: search and then exploit
"The idea that the objective may be the enemy of progress is a bitter pill to swallow, yet if the proper stepping stones do not lie conveniently along its gradient then it provides little more than false security"
Natural evolution did not originate as an optimization algorithm. Its only objective was survival long enough to reproduce. Within that minimal criterion, it supports a vast repertoire of neutral or mildly useful innovations — structures that neither harm nor help, but persist. Over deep time, many of these seemingly inconsequential variations were exapted into fitness-supporting adaptations.
Local competition for resources introduced selection pressure, giving rise to survival of the fittest dynamics. Yet the creative force in evolution came from maintaining diversity, not maximizing an objective. A canonical example is gene duplication. When a gene copies itself, one version continues its original function while the other becomes redundant. Occassionally however, that spare gene discovers a new role. The globin family, for instance, split into hemoglobins that transport oxygen in blood and myoglobins that store it in muscles.
In artificial evolution, Quality Diversity (QD) methods make explicit what natural evolution does implicitly. Instead of maximizing an objective, they reward diversity so that populations explore and tile the behavioral landscape. Once the behavioral landscape has been illuminated, local competitions for fitness refines the collection, preserving useful ones — an approach known as search and then exploit. QD-methods like MAP-Elites have for example been used to produce ~13,000 different gaits for a hexapod robot and adopt them under damage and terrain changes.
Neuroevolution is primed for an explosion
The success of neuroevolution depends on 4 key ingredients: the inclusion of the right structural priors on neural networks, effective evolutionary algorithms, ample compute and robotics hardware, and the presence of high-fidelity, continuously-changing and challenging optimization environments. Today, for the first time, all four conditions are converging.
Over the last few decades, evolutionary algorithms have matured dramatically — from simple genetic searches to QD and open-ended approaches. Compute is now abundant thanks to massive investment in AI infrastructure. Robotics hardware is also no longer a bottleneck. Work on challenging optimization environments continues with the introduction of platforms such as POET and OMNI-EPIC.
Yet, two exciting frontiers remain unexplored.
Architectural priors. What must a neural network have to do what we want it to do? What structural constraints and inductive biases make certain behaviors possible while keeping others out of reach? The challenge is to design models that are flexible enough for complexity to emerge, yet grounded enough to respect the finite nature of time and compute.
Developmental programs. Nature is able to use only 1 GBs of genetic code to encode a network of trillions of parameters because it makes use of sophisticated biochemical decompression machinery. Replicating a fraction of the capacity of this machinery in silico could make evolutionary algorithms significantly more powerful than they are.
I firmly believe that exciting times lie ahead for neuroevolution. By making full use of the abundance of compute to evolve large and complex populations, using heuristics such as QD methods to explore interesting regions of the search space, and creating even more powerful algorithms, we can build systems capable of continual, adaptive learning in complex environments.